The “brain” behind every modern AI, from ChatGPT to Llama, is a design called the Transformer. The Transformer architecture, introduced in the 2017 paper “Attention Is All You Need”, is the specific design that allows LLMs to understand context, meaning, and relationships across long pieces of text efficiently.
Before the arrival of Transformers, models processed text sequentially, like reading a book one word at a time from left to right. This made it hard to understand long-range dependencies. The Transformer solved this with a mechanism called self-attention. In simple terms, self-attention allows the model to look at every word in a sentence simultaneously and decide which other words are most relevant to understanding it. For example, in the sentence “The farmer planted maize because it was the rainy season”, the model looks at every word in a sentence simultaneously and calculates which words are most relevant to each other.
The two main components of a Transformer are:
- Encoder: This part reads and understands the input text. It analyzes the relationships between all words and creates a rich, contextualized representation of the sentence.
- Decoder: This part generates the output text (like a translation or an answer) word-by-word, constantly referring back to the encoder’s understanding.
Key Concepts and Definitions
- Transformer: A neural network architecture optimized for sequence data like text.
- Attention: A mechanism that lets the model focus on the most relevant parts of the input.
- Self-Attention: The model compares each word with every other word in the same sentence.
- Encoder and Decoder: Components that process input text and generate output text.
How Transformers Work Conceptually
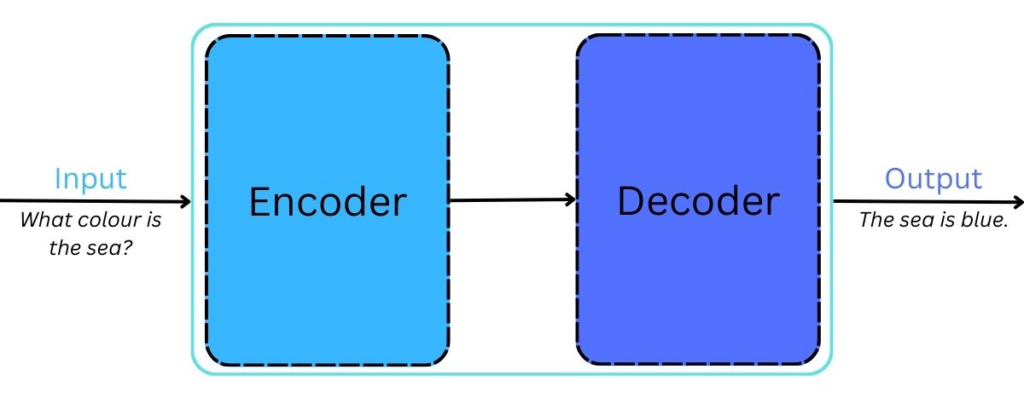
Imagine reading a sentence like: “What color is the sea?” To understand this sentence and predict the next sentence or provide an answer, a Transformer model performs the following steps:
- Converting each word into a numerical representation (known as Tokenization).
- Comparing every word with every other word using self-attention.
- Assigning higher importance to relevant word relationships.
- Passing this information through multiple layers to refine understanding.
- Performs a generative process to create the answer word-by-word.
Most modern LLMs, like GPT and Llama, are decoder-only models. They are exceptionally good at the task of “predicting the next word” in a sequence, which is the foundation of text generation. This architecture is what allows LLMs to write coherent essays, generate code, or answer your questions in a conversational way.